Learning 3D Dynamic Scene Representations for Robot Manipulation
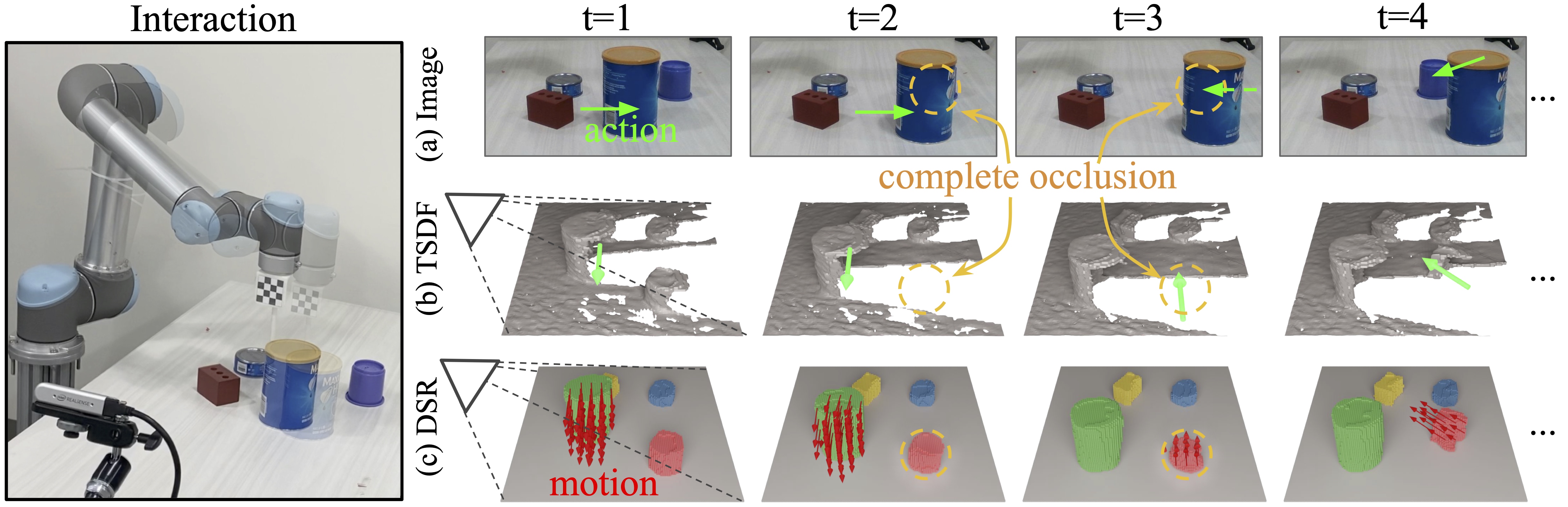
3D scene representations for robotic manipulation should capture three key object properties: permanency - objects that become occluded over time continue to exist; amodal completeness - objects have 3D occupancy, even if only partial observations are available; spatiotemporal continuity - the movement of each object is continuous over space and time. In this paper, we introduce 3D Dynamic Scene Representation (DSR), a 3D volumetric scene representation that simultaneously discovers, tracks, reconstructs objects and predicts their dynamics, while capturing all three properties. We further propose DSR-Net, which learns to aggregate visual observations over multiple interactions to gradually build and refine DSR. Our model achieves state-of-the-art performance in modeling 3D scene dynamics with DSR on both simulated and real data. Combined with model predictive control, DSR-Net enables accurate planning in downstream robotic manipulation tasks such as planar pushing.
Paper
Latest version: arXiv
Conference on Robot Learning (CoRL) 2020

Team




1 Columbia University 2 Stanford University * Indicates equal contribution
BibTeX
@inproceedings{xu2020learning,
title={Learning 3D Dynamic Scene Representations for Robot Manipulation},
author={Xu, Zhenjia and He, Zhanpeng and Wu, Jiajun and Song, Shuran},
booktitle={Conference on Robot Learning (CoRL)},
year={2020}
}Technical Summary Video (with audio)
Dataset Overview

We build a new benchmark dataset with 150 sequences (1,500 interaction steps) for evaluating dynamic 3D scene representations. Here are some samples of real world data. Scene observation(left) is captured by a RGB-D camera. Object instances(right) are visualized in different colors. In each step, the robot executes a random pushing action(green arrow) and the objects' motion is visualized in red arrows.
Amodal Mask and Motion Prediction
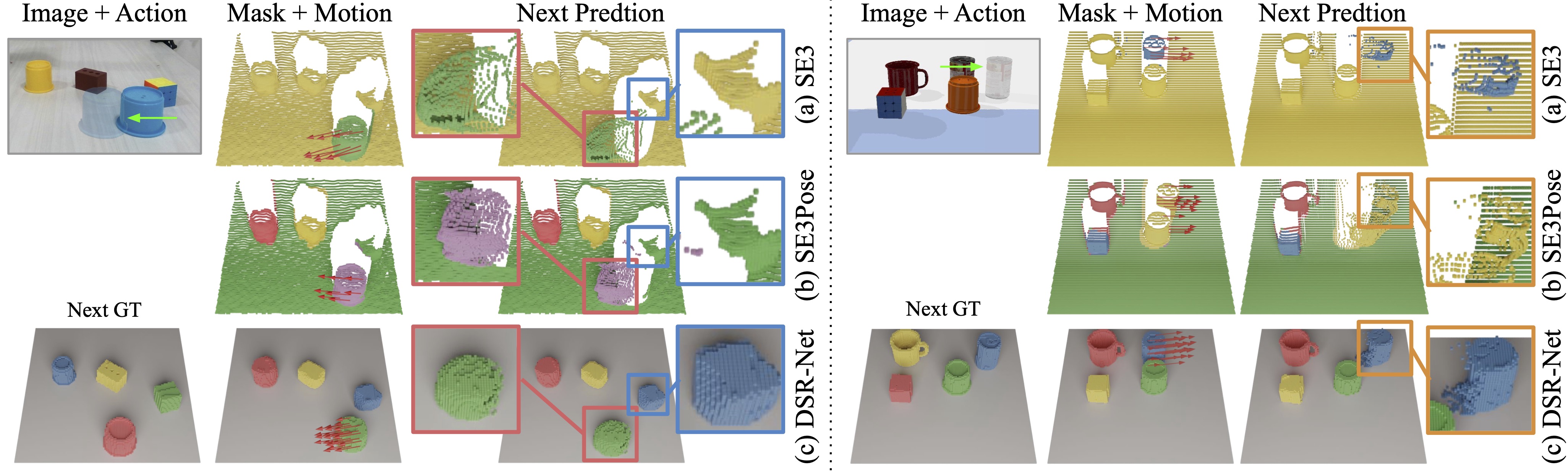
This figure presents the mask and motion prediction of SE3-Net and DSR-Net in both real-world (left) and simulation (right). SE3-Net predicts only masks for moving objects and the estimated motion is limited to the visible surface. Although the mask prediction in SE3Pose-Net is not limited to moving objects, it fails to separate closed objects and miss small objects. DSR-Net produces the full 3D volume as well as masks for all objects in the scene.
Object Permanence
Object permanence is the understanding that objects continue to exist even if they disappear from view due to occlusion.

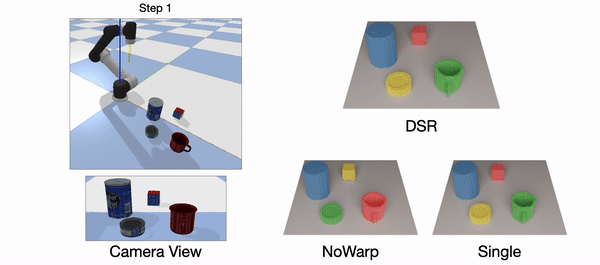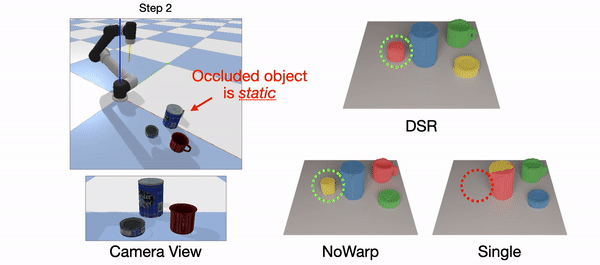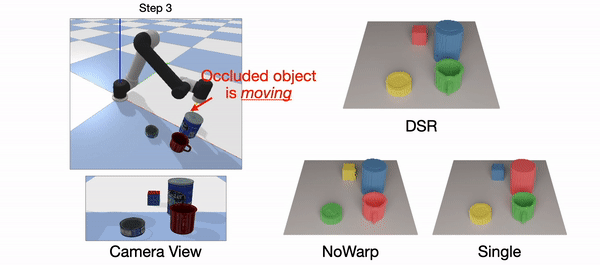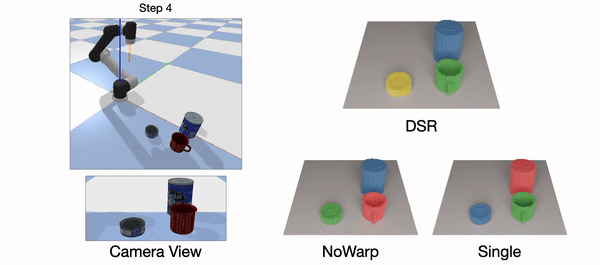
Real-world(left): The green cup is occluded by the can. Only DSR-Net is able to predict the permanence of the green cup.
Simulation(right): Occlusion appears in the step=2 and step=4. The difference is that from step=1 to step=2, the occluder (can) is pushed and occludes the Rubik’s Cube, and from step=3 to step=4, the object being occluded (Rubik’s Cube) is pushed and hide behind the can. SingleStep fails in both cases. NoWarp can handle the first case since the history contains the information of the static Rubik’s Cube. NoWarp can’t handle the fourth step of the simulation data due to the lack of motion in history. Our DSR-Net can handle all these occlusion cases.
Object Continuity
Object Continuity means the representation can recognize individual object instance and track their identity over time.

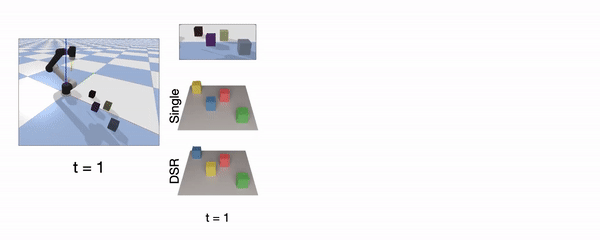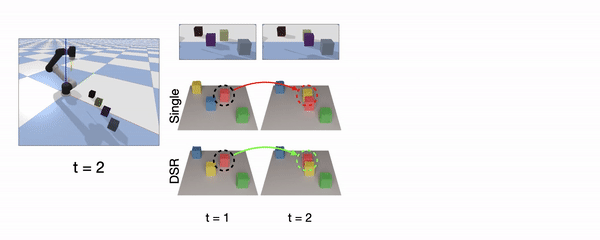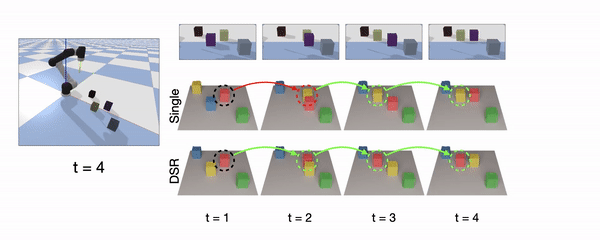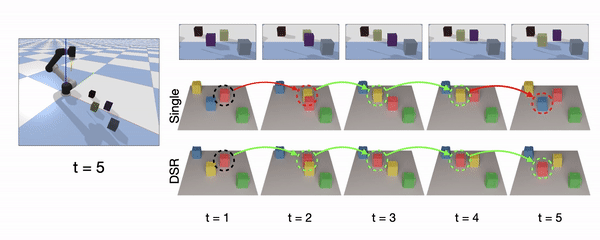
Continuous instance prediction between two consecutive steps is highlighted in green, while discontinuity is highlighted in red. Unlike the SingleStep model, which is sensitive to the spatial order, our model maintains spatiotemporal continuity via consistent labeling of object instances. In the simulation demonstration (right), positions of four visually indistinguishable objects are swapped after several interactions. The depth observations of the first and last steps are almost the same, but out DSR-Net can still track the identities of these objects. It proves that the continuity owes to history aggregation, instead of visual appearance.
Robot Manipulation: Planner Pushing
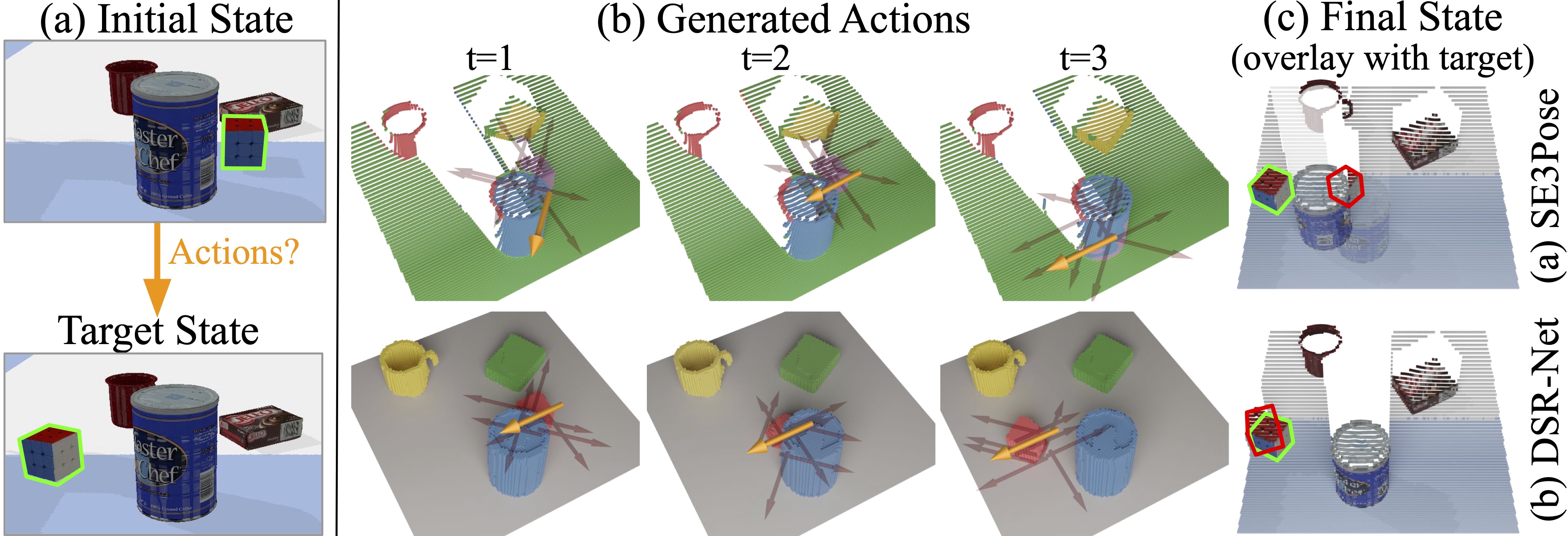
(a) The goal is to generate a sequence of actions to push objects to match a target state. (b) In each step, a set of action candidates are sampled and the action with the lowest cost (yellow) is chosen to execute. At t = 3, SE3Pose-Net loses track of the occluded object hence choose the wrong action, while DSR-Net correctly models the occluded object and chooses appropriate actions. (c)The final state (red) of DSR-Net is much closer to the target state (green)
Acknowledgements
We would like to thank Google for providing the UR5 robot hardware for our experiments. This work was supported in part by the Amazon Research Award, the Columbia School of Engineering, as well as the National Science Foundation under CMMI-2037101.
Contact
If you have any questions, please feel free to contact Zhenjia Xu.